 Past Technology: Lights and Mirrors
Past Technology: Lights and Mirrors
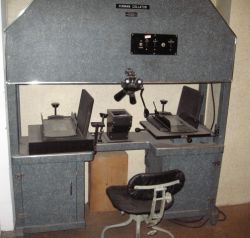
The students at the University of Virginia Rare Book School, receive, as part of a course in Advanced Descriptive Bibliography, a demonstration of the 450 pound Hinman Collator. The purpose of the machine, which was developed during the 1940s by Charlton Hinman, was to help detect typographical variations in the printing of early editions of a particular title. It is, in a way, an invention which can be used to identify a first printing from a later printing by comparing text one page at a time. The two copies are laid on the machine’s platform side by side and are superimposed via a set of mirrors causing variations in text to appear wiggling about through the machine’s pair of binocular optics.
The most famous task that the machine was used for was to compare Shakespeare’s plays, of which no manuscript survives. During the Renaissance, it was common practice during the printing process, to proofread and correct continually, leaving changes scattered throughout various copies as a trail by which bibliographic research could determine the order by which copies had been printed. Using his then state of the art technology, Hinman was able to compare 82 volumes of 900-plus pages, scrutinizing two pages at a time. A process he once estimated would have taken him 40 years, if ever completed, without the machine.
In the years following Hinman, various attempts were made to improve the technology primarily by condensing its size. The most notable improvement was the portable model developed by Randall McLeod during the late 1990s. By then, computers were leaping ahead in the technological innovation race, with the introduction of portable scanning devices that have become common practice today.
Digitization and Datafication
It has been a year since a US federal appeals court ruled that Google’s book-scanning project was in compliance with copyright laws even when volumes were scanned without the authors’ permission. The project, which now includes Optical Character Recognition (OCR) technology, to convert scanned images into text, is making it easier for readers to find works, and researchers to compare and analyze. The digitization of books is combined with data indexing to provide datafication of contents and a powerful search capability against the Big Data of the written word.
The future is now: Machine intelligence
The next generation of technology is now beginning to evolve. Fast pixel-to-pixel comparison through portable devices such as a mobile phone backed by the availability of relevant statistical data, is providing the platform for killer application development. New development is already underway utilizing complex mathematical inference learning algorithms to identify and compare books through their cover imagery using a phone camera to input. Extending functionality beyond the barcode scanner, the pixels of the covers and pages are matched against the database to determine the authenticity, value and scarcity of a particular edition.
Digitally produced images such as the ones on facsimile book dust jackets are made of ink jet dots rather than the vintage offset lithographic dots. Dots relate to the droplets of ink a printer spits to produce images in detail and are measured in DPI or “Dots per Inch”. Ink jet dots are generally smaller than vintage offset lithographic dots that are produced by pressing ink directly onto paper.
All digital images are made up of tiny squares called pixels, and each pixel in an image has a specific size and a specific color value. It takes multiple drops of ink from the printer to create the color in each square pixel. Under normal circumstances, digitally produced images contain more dots per pixel than those produced through lithography. Facsimile book dust jackets consist of pixels that contain smaller dots with greater variation in color in their composition than original dust jacket pixels which are made of larger dots with more color consistency.
Engineers at Google that have worked on providing well optimized image search engine results using the information contained within images, are now developing machine intelligence applications that are using pixel patterns to infer the identity of an image. By reversing this same process, they are able to produce an image from an object’s identity. Not too long from now, bibliophiles may carry phone apps that use the phone’s camera to match book cover images to a detailed set of data, or use book attributes to generate an image of what the book could look like. Foxing and chipping still included!
{ 1 comment… read it below or add one }
Very interesting article. We have certainly come a long way with technology. So I guess sooner or later sellers will be scanning not only isbn codes but the dustjackets themselves also for authenticity.
{ 2 trackbacks }